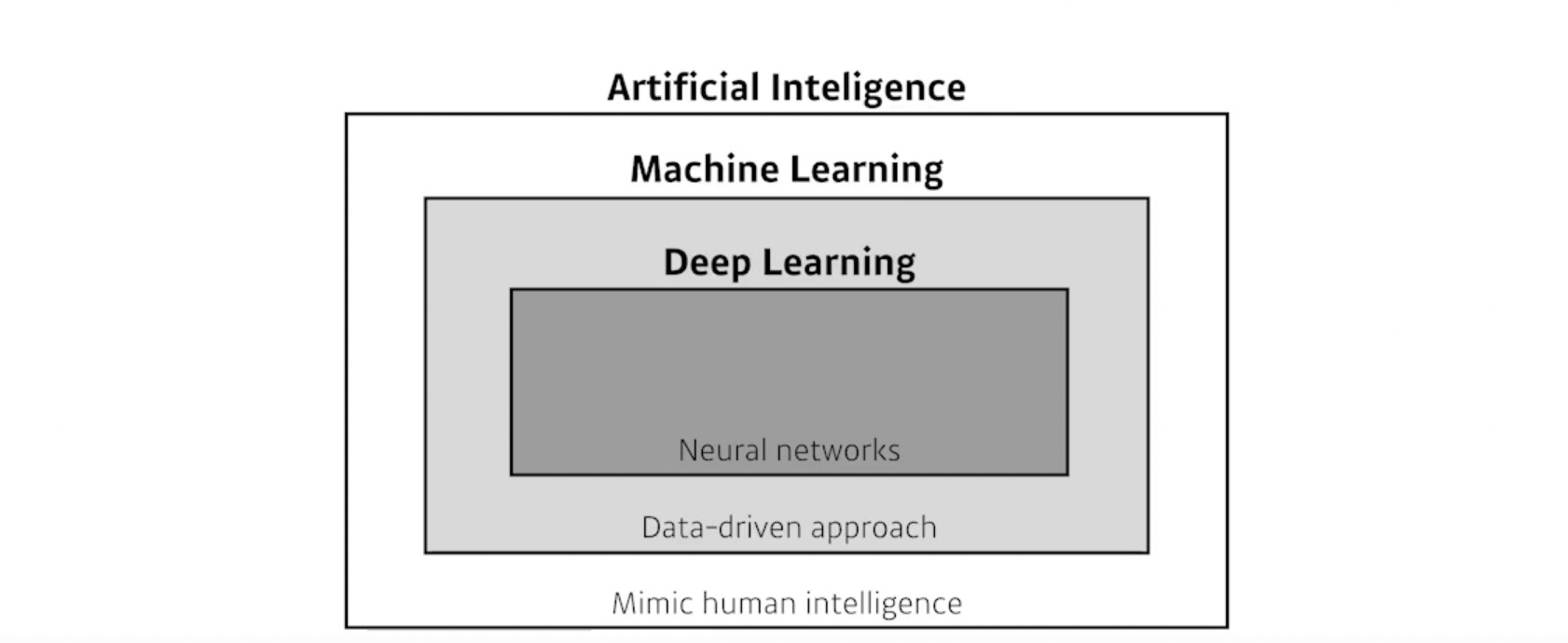
Deep learning basic
Deeplearning
model
- 정의 : 이미지가 주어지거나, 텍스트가 주어졌을때, 이러한 단어를 내가 직접적으로 알고 싶어 하는 문장에 대한 sentimental elemnet(?)를 바꾸어주는 모델이 된다.???
Loss function
- 정의 : 모델이 정해져있고, 데이터가 정해져있을때, 이 모델을 어떻게 학습할지?? 딥러닝을 다룬다면 어떻게든 뉴럴네트워크를 갖게 될텐데, 이 뉴럴네트워크는 각 layer에 있는 weight와 bias를 의미
- 예시
- Regression Task -> MSE
- Classification Task -> CE (Cross entropy라 불리는 것들을 최소화함)
- Probablic Task -> MLE(Maximum Likelihood Estimation)
Optimization
- 일반적인 방법 : first order method -> neural network의 parameter를 loss function에 대하여 1차미분한 정보를 활용!
- training error 가 0이 되면 좋은걸까? 학습에 사용하지 않은 데이터에 대해서는 성능이 떨어지기도 한다. -> overfitting
- 대안 : Cross - validation : 학습데이터를 k개로 나누고, 이 k개를 어떨때는 학습데이터, 어떨때는 validation data로 번갈아 가면서 쓴다.
- Bias - variance trade off -> bias를 줄이면 variance가 올라가고, variance를 줄이면 bias가 올라가는 trade off 가 있다.

Neural Network
의미: 함수를 근사하는 모델 (행렬연산과 비선형 연산이 반복적으로 일어나는)
예시 : 가장 간단한 linear regression : 입력이 1차이고, 출력이 1차일때, 함수를 찾는것
나의 파라미터를 어느방향으로 줄였을때, loss가 줄어드는지 파악해야함
하지만, 딥러닝은 만만하지 않다. 선형이 아니라서, loss function의 모든 변수에 대해서 미분을 해야하는 back propagation 과정이 있음. 그 backpropagation의 그래디언트를 업데이트하는 gradient descent 과정이 있음
인풋과 아웃풋이 다르다면 행렬을 이용해 n차원에서 m차원으로 바꾸자.
*
네트워크를 여러층 쌓으려면, 네트워크가 표현할 수 있는 것을 극대화하기 위해서는 단순히 선형결합을 n번 반복하는게 아니라, 그 뒤에 activation 함수를 거쳐서 nonlinear transform 을 거쳐서 얻은 feature vector를 다시 선형변환하는것
Convolution
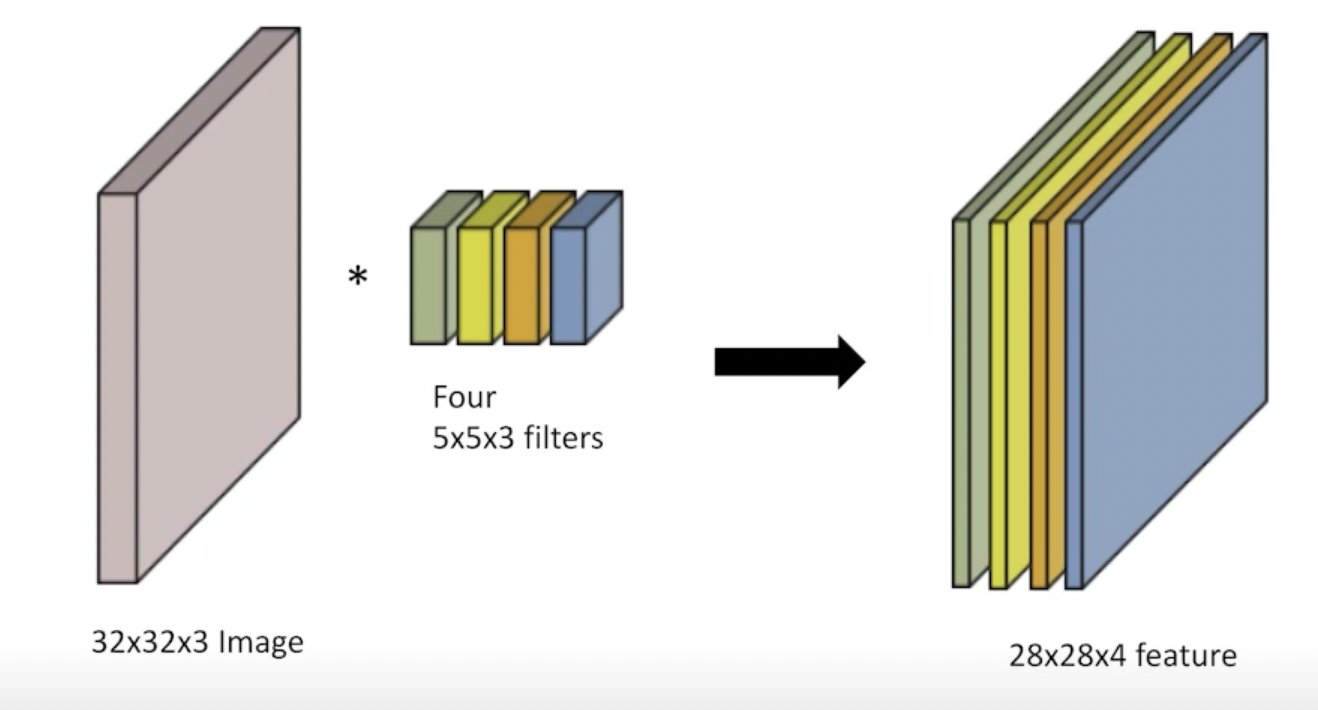
- 의미 : 두개의 함수를 잘 섞어주는 operator로서의 역할을 함
- convolution filter에 따라서 이미지가 blur, emboss, outline이 될 수 있다.
- Input channel 과 output channel을 알면 , convolution에 적용된 filter를 알 수 있다.
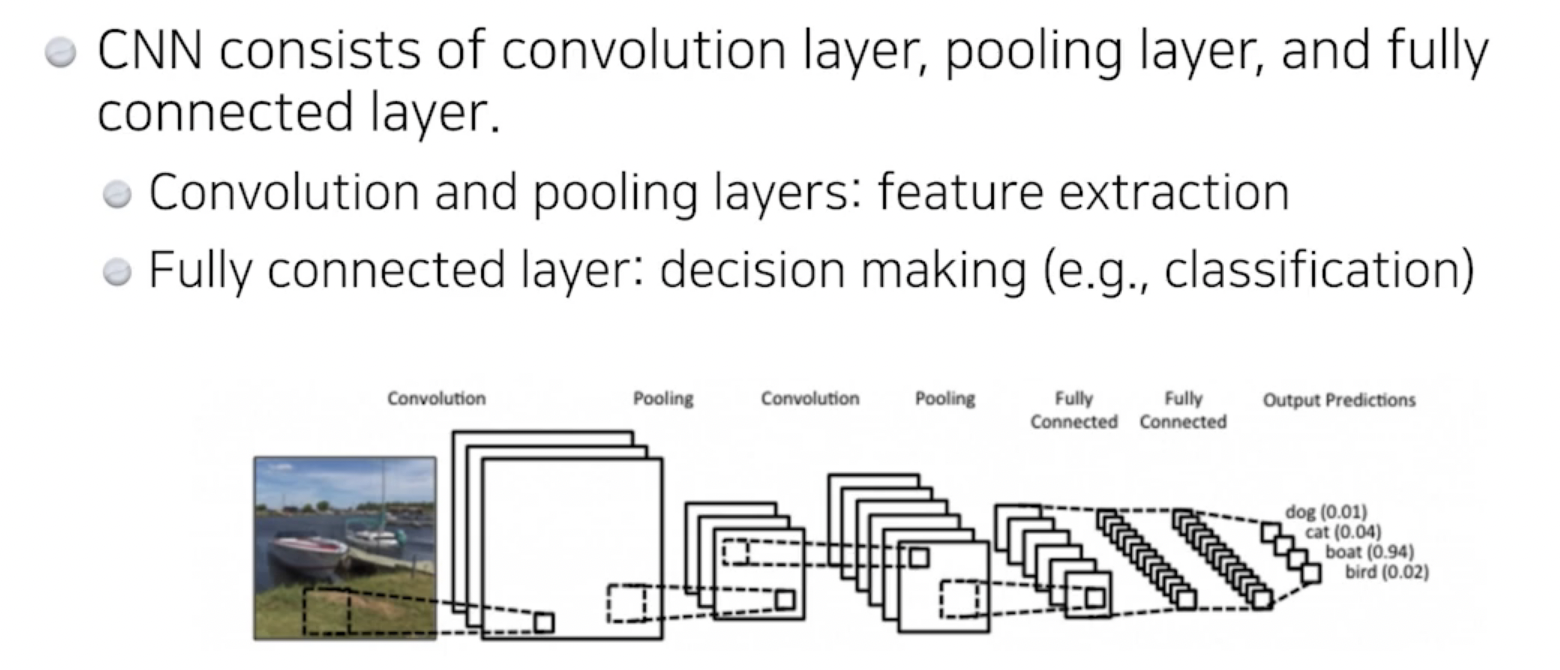
- convolution과 pooling network가 해주는것은 이미지에서 중요한 feature를 뽑아내는것
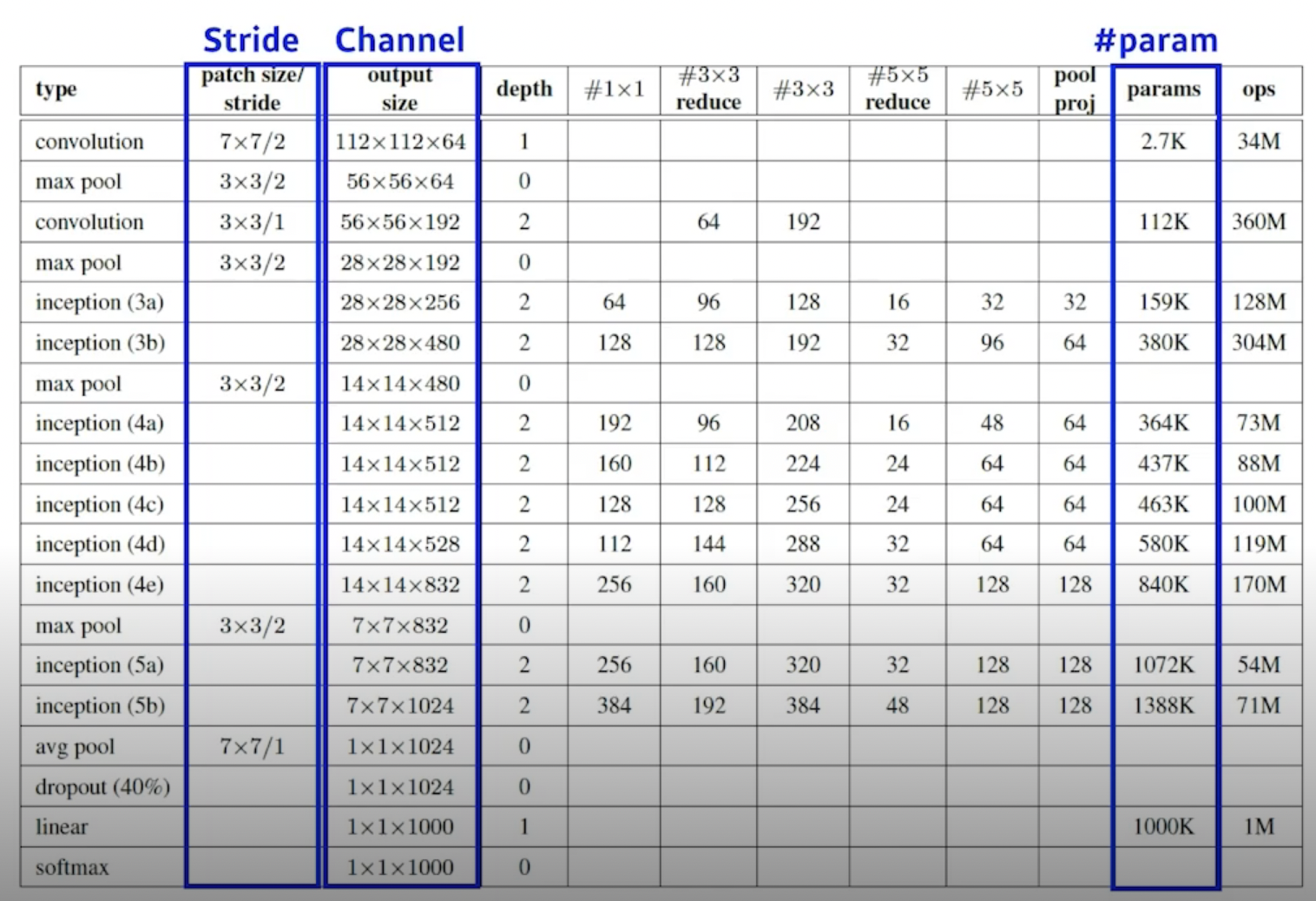
- 모델의 파라미터 숫자가 많아질수록, 학습이 어렵고, generalizing performance가 떨어진다. 그래서, CNN 의 목적성은 deep하게 학습을 하지만, 최대한 파라미터 숫자를 줄이려고 한다. 어떤 네트워크를 보았을때 중요한 것은, 각 layer별로 파라미터가 몇개로 이루어져있는지를 파악하는것
- **중요한것 ** : 이 표를 보고 각 파라미터의 숫자를 직접 손으로 계산해보고 맞는지 확인하기
Semantic segmentation
- 문제 : 이미지의 모든 픽셀이 어떤 라벨에 속하는지 알고 싶은데, 이게 굉장히 어렵다.
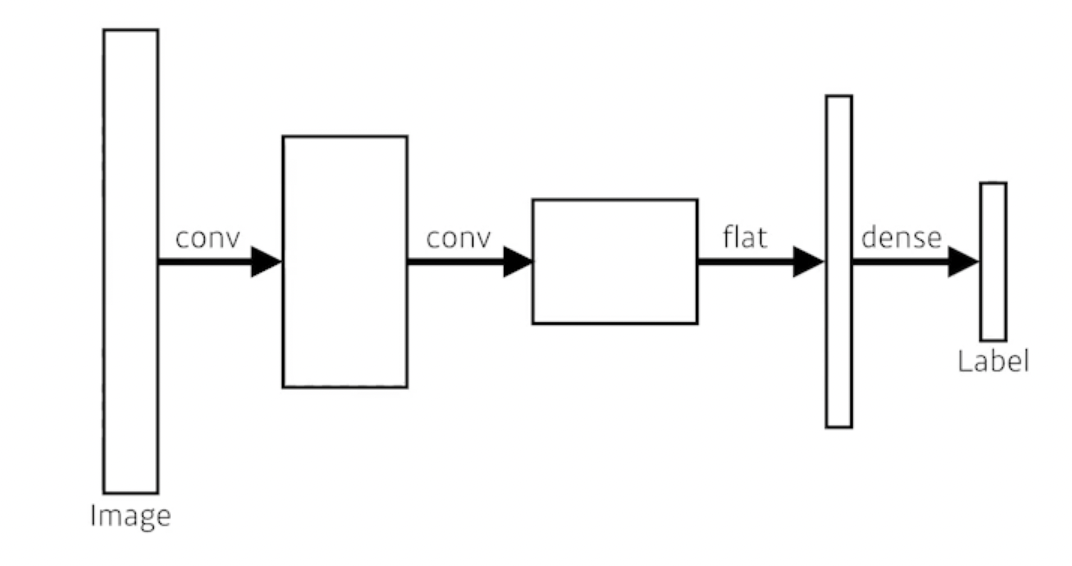
- 그림과 같이 dense layer을 없애고 싶다. 그래서 이 과정을 convolutionalization. 왜 이런 짓을 할까?
- 이미지가 커지면, 그것을 fully convolutional network를 하면 단순히 분류만 했던 것이 이제는 semantic하게 나타낸다.
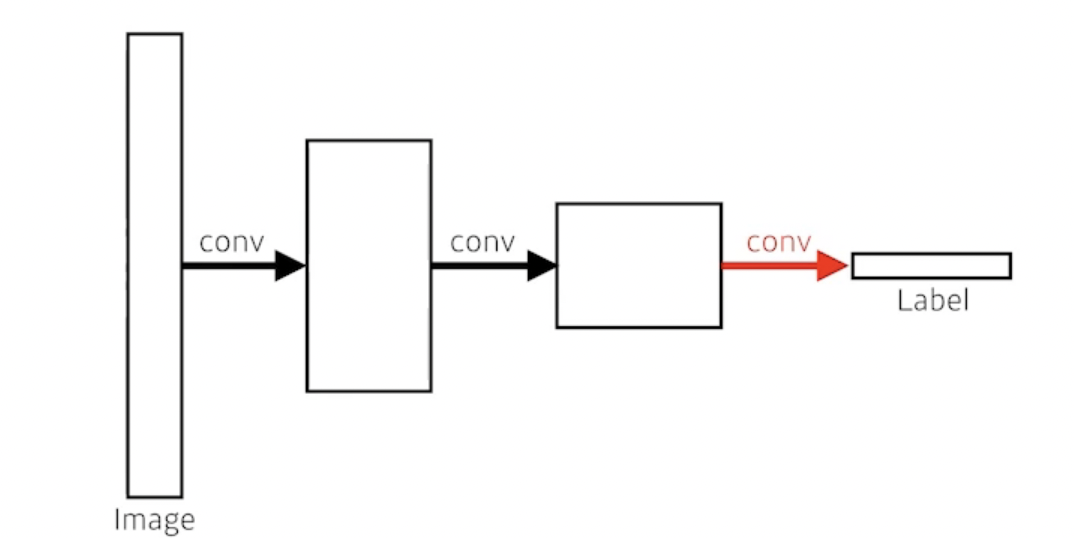
- Deconvolution -> convolution의 역연산
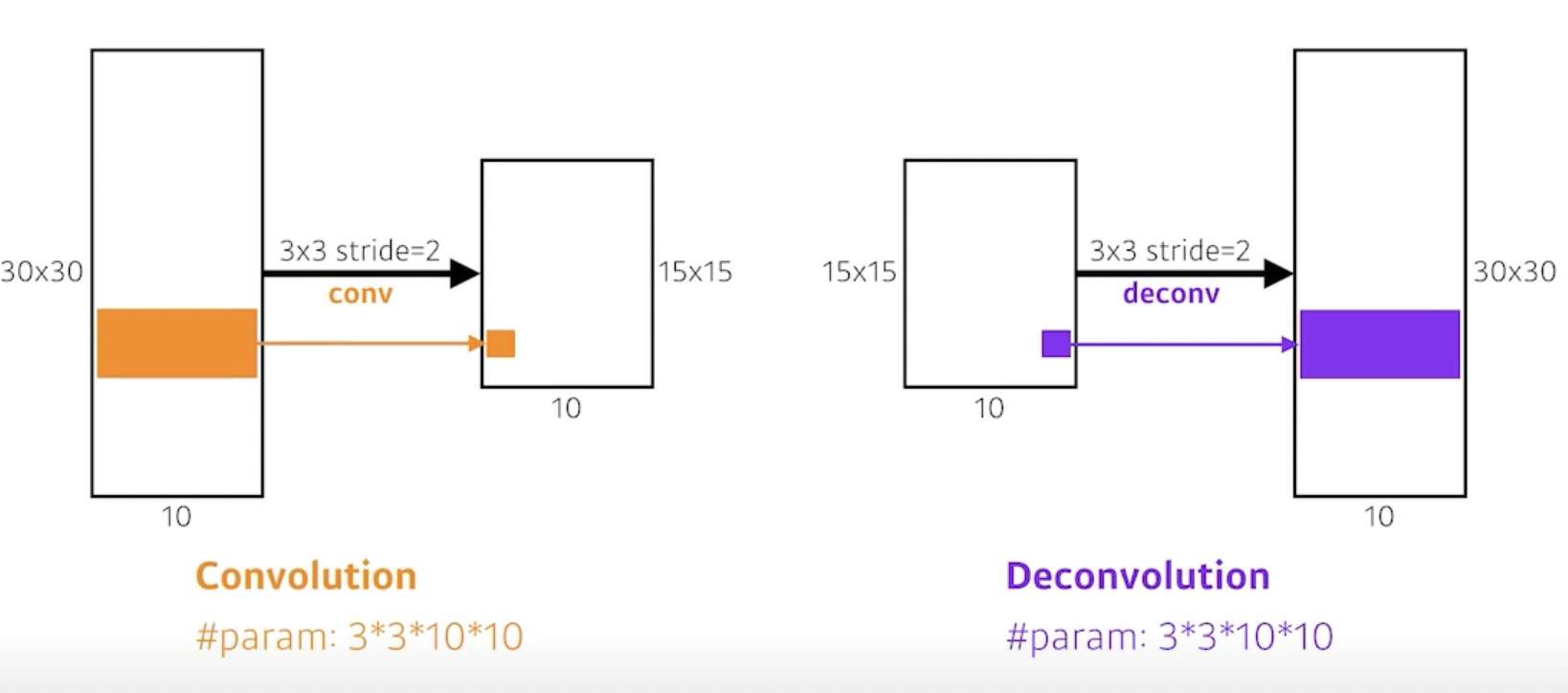
- 엄밀히 말하면 역은 아니지만, 파라미터의수와 input과 output의 수를 보았을때, 역으로본다.
Detection
R - CNN
- image안에서 patch를 한 2000개 정도 뽑은 다음, 똑같은 크기로 맞춘다음, 분류를 한다(support vector machine이용)
- 문제 : 2000개의 patch를 전부 CNN에 돌린다. 시간이 많이 걸림
SPPNet
- image안에서 bounding box를 뽑고, 이미지 전체에 대해서 convolution feature map을 만든다음에, 뽑힌 그 bounding box에 해당하는 convolution feature map의 tensor만 뽑아내자.
Leave a comment