Gradient Descent
Gradient Descent
-
Intuition: Imagine you’re lost in the mountains — how would you find the lowest point? Just keep walking in the direction with the steepest downward slope. That’s the essence of gradient descent.
-
Goal: To find the minimum of a function, especially useful when the function is not closed-form or hard to differentiate analytically.
-
Mathematical Derivation: How do we determine where to move
xto reach the minimum? -
When dealing with vector variables, use partial derivatives.
-
The closer you are to the minimum, the smaller the steps you should take.
-
Compute the gradient vector using partial derivatives for each variable and use this in gradient descent.
-
The negative gradient vector points in the direction of the steepest descent. We often normalize it (use its norm).
-
Let’s apply gradient descent to linear models. While Moore-Penrose pseudoinverse works for linear models, gradient descent also works for nonlinear ones.
-
Why use the gradient vector?
In any space, the gradient vector at a point indicates the direction toward the minimum. Use this to move toward lower cost.
Objective Function for Linear Regression
\[\lVert y - X\beta \rVert_2\]
y: the target output in our datasetLinear model:
X * betaGoal: Minimize the L2 norm of the difference
The objective function to minimize:
- We solve the objective function using derivatives:
Represented using the gradient vector
To get the (t+1)th value, subtract the gradient from the t-th value
Theoretically, gradient descent converges for differentiable and convex functions
However, for nonlinear regression problems, convexity is not guaranteed → Problem
Solution: Stochastic Gradient Descent (SGD)
Even though it uses only a portion of the data, its performance is often comparable to using the full dataset.
In deep learning, SGD is preferred due to drastically reduced computation.
Example 1: Predicting a Value from One Input
- Given data like
hoursandpoints, how do we evaluate model quality?- We use a cost function (difference between predicted and actual values).
- The cost function is a quadratic function with respect to
w.
- If the slope is negative → increase
w.- If the slope is positive → decrease
w.- Use the gradient to reduce the cost.
Minibatch Gradient Descent
- Learn using only a subset of the dataset instead of the entire dataset.
- This allows for faster updates, though there’s a risk of updates in the wrong direction.
Why Batch Size Matters
- Smaller batch sizes tend to improve generalization performance.
- How can we still take advantage of large batch sizes?
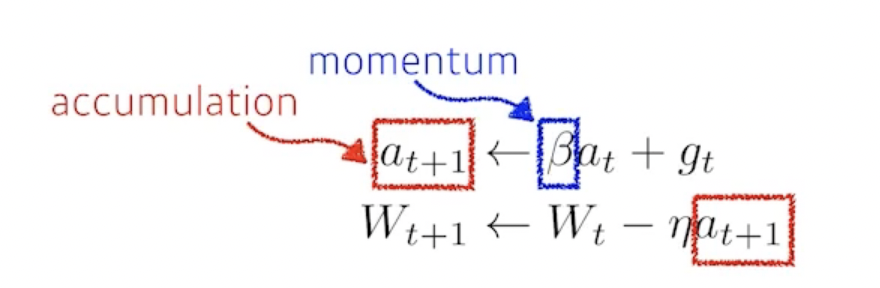
Momentum
- How can we further improve performance?
- If the gradient flows in a particular direction, keep some of that direction for the next update.
Regularization
-
Definition: Apply constraints to training data so the model generalizes well to unseen test data.
-
Methods:
-
Early Stopping
Stop training early and validate on held-out data. -
Parameter Norm Penalty

Encourage smaller weights during training. -
Data Augmentation
Increase training data by transforming inputs while preserving labels. -
Noise Robustness
Inject noise into weights or inputs during training. -
Label Smoothing
Blend labels — mix two samples and their labels accordingly. -
Dropout
Randomly drop units during training to prevent overfitting.
-
Leave a comment