Link
Project notebook (Colab / Jupyter):
https://github.com/superchd/AI/blob/main/FMA_Prediction.ipynb
Current Goal
- Use FMA-UE scores at 7 days, 30 days, and 1 month to predict the FMA score at 1 year.
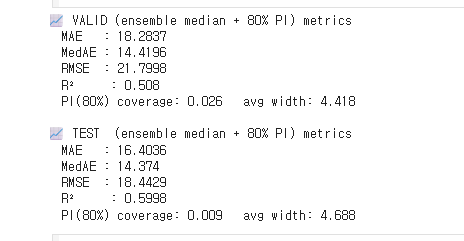
However, the current results are not satisfactory:
- The difference between the predicted mean and the true mean is very large.
- Overall calibration of the model is poor.
Planned Next Steps
Ideas to try next:
- LSTM-based sequence model
- Treat FMA over time as a short time series (7d → 30d → 1m → predict 1y).
- Change prediction horizon
- Instead of 1-year prediction, try:
- 30-day (or 7-day) data → predict 3-month or 6-month FMA.
- Instead of 1-year prediction, try:
- If the above still fail,
- It may not be realistic to do regression to exact 6–12 month scores with the current dataset.
Alternative Modeling Ideas
Right now, the target is the total FMA score.
One alternative:
- Predict all 32 FMA item scores individually, then sum them afterward to get the total.
- However, after thinking this through, it seems that with the current data it is still very hard to accurately predict the 6-month score in a stable way.
Because of this, I realized:
- It may be better to avoid direct regression to the exact total score.
- Possible options:
- Remove extreme outliers.
- Split patients into 3 groups (e.g., high / medium / low).
- Switch from regression to classification (e.g., predict recovery category instead of exact score).
At the moment, even within these groups, the correlations are very low, so further feature engineering or reframing of the prediction task is needed.