도입부
범주형 데이터 분석시 사용시 통계적 검정 방법
예를들어, 과일을 묻는 설문조사에서 답변이 범주로 나뉘는 데이터
좋아하는 과일 -> 사과 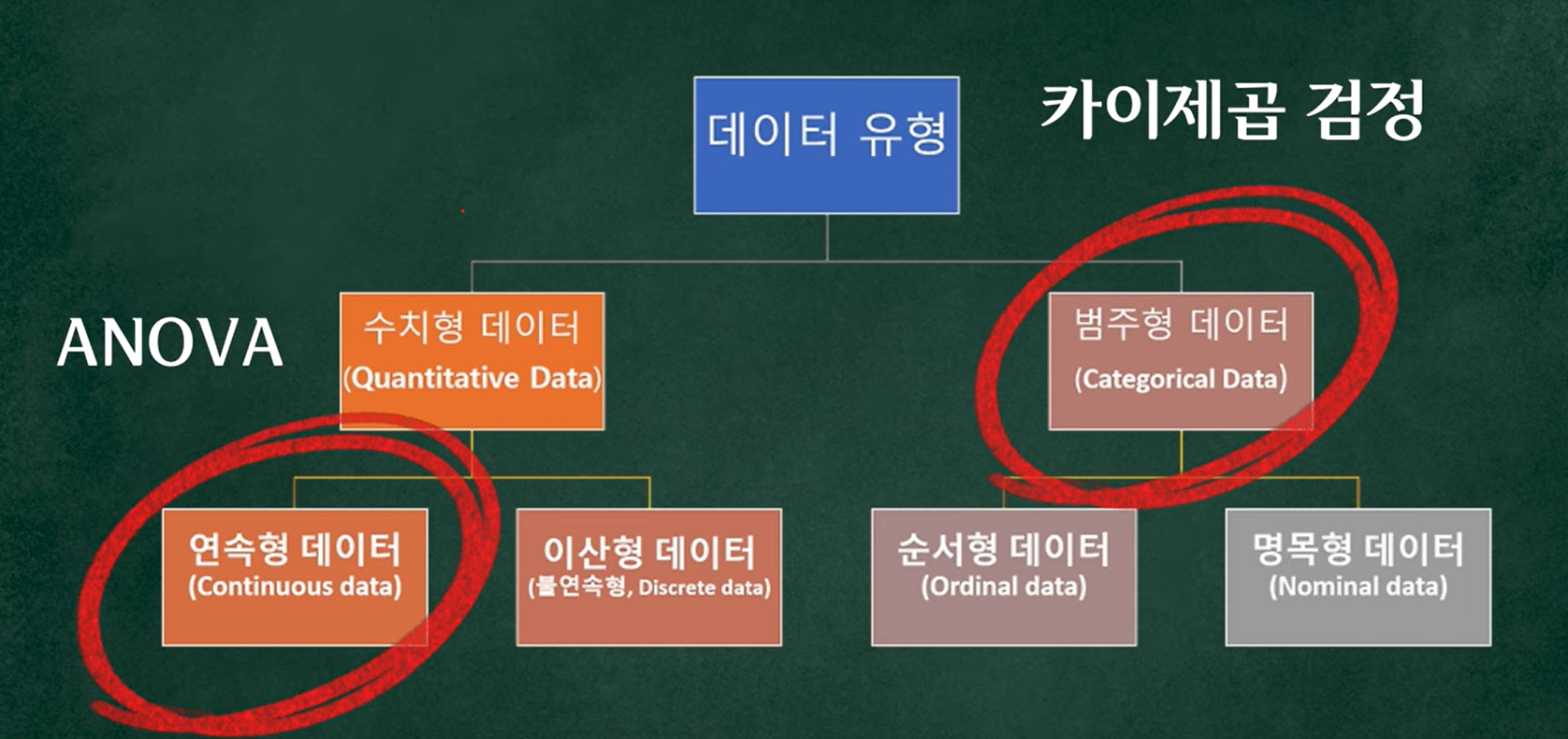 , 포도
, 포도
연속형 -> 키 , 몸무게 , T-test, anova
카이제곱 검정이 필요한 이유
통계적으로 유의미한 질문을 해본다면 사람들이 과일을 고를때 특정한 패턴이 있을까?
예를들어, 30대가 20대보다 사과를 더 좋아할까? 같은 질문
설문조사 결과만 보면 어떤 패턴이 있는지 알수 없음
이럴때 사용하는 것이 카이제곱 검정!
간단히 말하자면 카이제곱 검정은 관측된 데이터, 기대되는 데이터가 얼마나 다른지 확인하는 도구이다.
예를들어, 사과, 바나나, 포도가 모두 똑같이 인기 있을것이라고 생각했는데 실제로는 사과가 압도적으로 인기 있다면 이 차이를 분석할 수 있는 방법이 카이제곱 검정
카이제곱 검정 종류
적합도 검정(goodness of fit test)
-> 특정 분포에 데이터가 적합한지를 검정
예를 들어, 과일선호도가 사과, 바나나, 포도 각각 1:1:1 비율인지를 확인하는 방법이 있다.
독립성 검정(test of independence)
-> ?
예를 들어, ‘과일 선호도’가 ‘나이대’에 따라 달라지는지를 확인한다.

이 데이터를 통해 귀무가설 설정이 가능하다!
귀무가설 : 나이에 따라 과일 선호도가 차이가 없다.
대립가설 : 나이에 따라 과일 선호도가 차이가 있다.
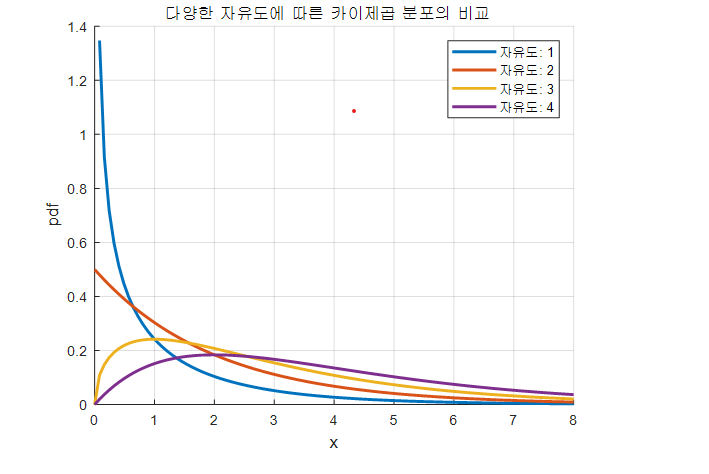
다양한 자유도에 따른 카이제곱 분포의 형태
카이제곱 분포는 통계량의 정의 상 표준정규분포로부터 얻은 랜덤 변수들을 “제곱”해 더하기 때문에 양의 확률변수에 한해서만 존재한다는 것을 알 수 있다.
또, “더한”것이기 때문에 더해주는 변수의 수가 많아질 수록 정규분포에 가까워진다. (중심극한정리)
관측값과 기대값
관측값 : 실제로 관측된 값
기대값 : 데이터를 보기전에 가정한 ‘독립적이라면 나타날 데이터’의 예상치
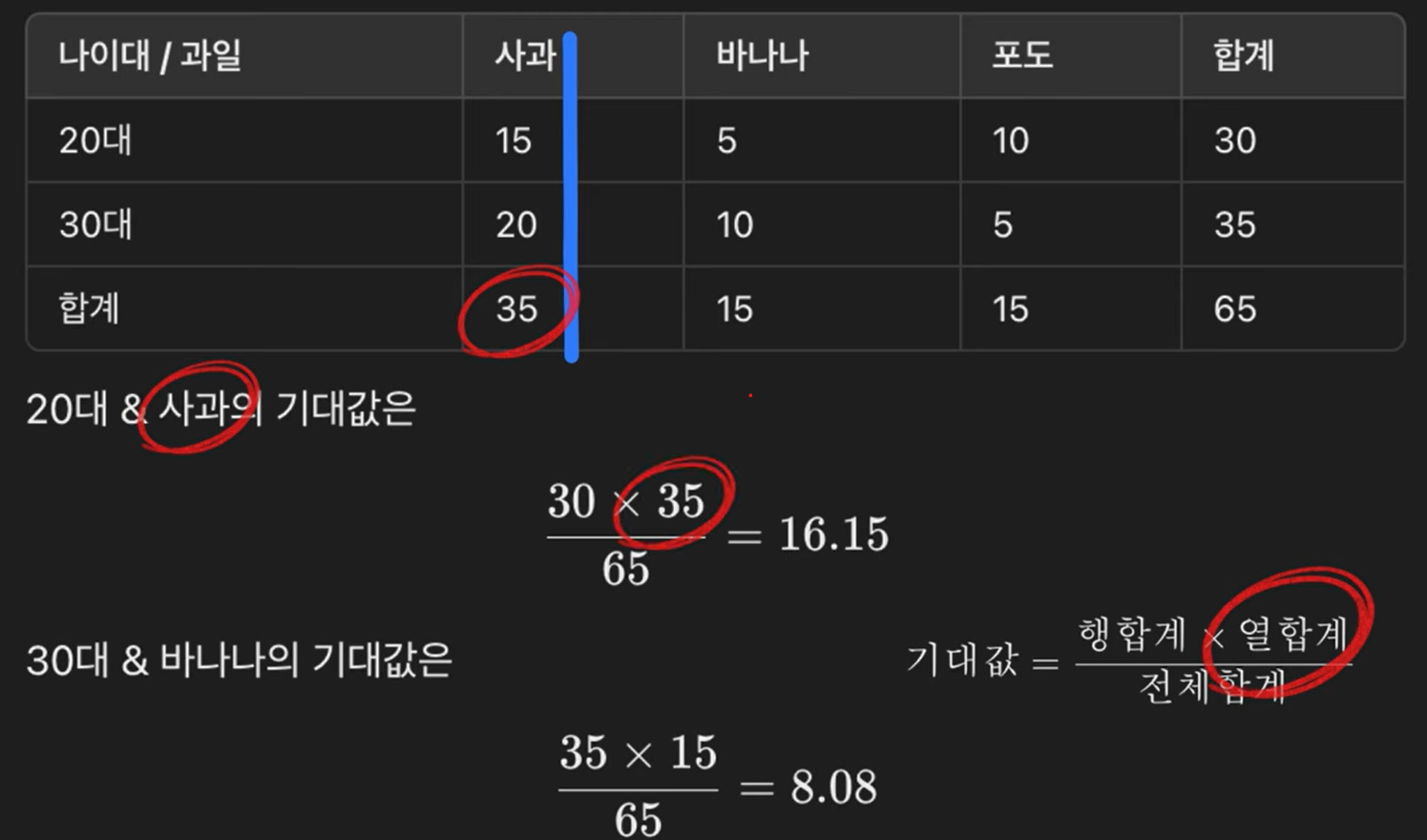
카이제곱의 귀무가설은 “두 변수가 독립적이다”라고 가정을 했기 때문에 곱셈법칙에 의하여
관측값과 기대값을 모두 구하면 카이제곱을 구할 수 있다.
**자유도 = (행의 범주수 - 1) * (열의 범주수 - 1) **
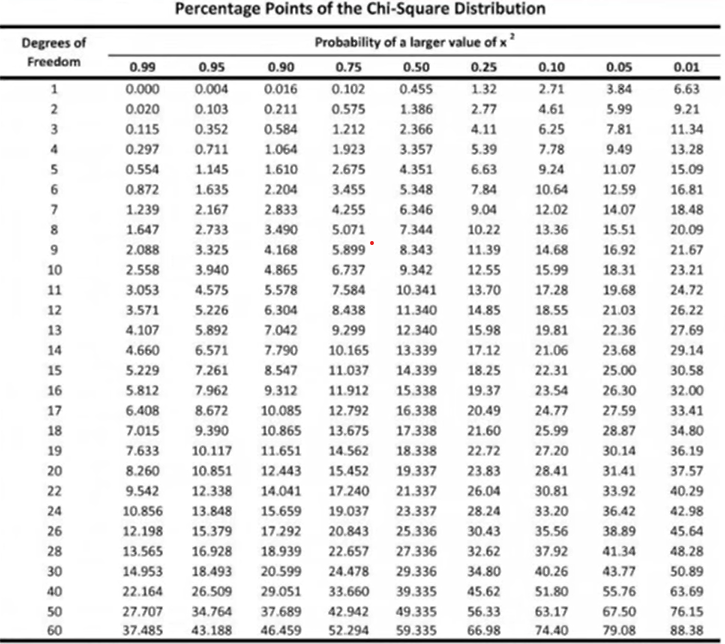
카이제곱 분포표
자유도와 카이제곱 값을 구해서 컴퓨터의 도움을 받아 p-value를 구하거나 카이제곱 검정표를 통해서 임계치를 구해야한다.
카이제곱 검정표를 구하기 귀찮은 사람들을 위해서 p-value 구하는 공식을 한번 알아보자!
\[p = \int_{x}^{\infty} \frac{1}{2^{k/2}\,\Gamma\!\left(\frac{k}{2}\right)} \, t^{\frac{k}{2}-1} e^{-t/2} \, dt\]그만 알아보쟈 ….
예를 들어, 자유도가 2일 때 유의수준 alpha를 0.05로 설정했다면 임계치는 5.99이다.
우리가 구한 카이제곱값 6.8이 더크다!
카이제곱값이 임계값보가 크므로 귀무가설을 기각한다.
예제: 카이제곱 적합도 검정 – 정규분포가 spermatogenesis 나이에 잘 맞는가?
문제 10.50 (요약)
정자 생성이 처음 관찰된 나이(age at spermatogenesis)가
정규분포로 잘 설명되는지 확인하고 싶다.
10.47–10.49에서 얻은 결과(표본 평균, 표준편차, 구간별 확률)를 이용하여
카이제곱 적합도 검정을 수행하라.
대표본 근사(large-sample method)가 가능하다고 가정한다.
1단계: 데이터(관측도수 (O_i))
나이를 네 구간으로 묶은 데이터는 다음과 같다.
- 11–13세: 9명
- 13–14세: 11명
- 14–15세: 10명
- 15–18세: 3명
총 표본수는
\[n = 9 + 11 + 10 + 3 = 33\]이 값들이 관측도수 $O_i$ 이다.
| 나이 구간 | 관측도수 (O_i) |
|---|---|
| 11–13세 | 9 |
| 13–14세 | 11 |
| 14–15세 | 10 |
| 15–18세 | 3 |
2단계: 정규분포 모형과 기대도수 (E_i)
10.47–10.49에서 나이에 대해
\[\text{Age} \sim N(13.67,\; 0.89^2)\]라고 가정한다.
이 정규분포로부터 각 구간에 속할 확률을 구하면 대략 다음과 같다.
- 11–13세: $p_1 \approx 0.224$
- 13–14세: $p_2 \approx 0.419$
- 14–15세: $p_3 \approx 0.288$
- 15–18세: $p_4 \approx 0.068$
총 표본수는 $n = 33$ 이므로, 기대도수 $E_i$ 는
\[E_i = n \times p_i\]로 계산한다.
- $E_1 = 33 \times 0.224 \approx 7.4$
- $E_2 = 33 \times 0.419 \approx 13.8$
- $E_3 = 33 \times 0.288 \approx 9.5$
- $E_4 = 33 \times 0.068 \approx 2.2$
정리하면 다음과 같다.
| 나이 구간 | 관측도수 (O_i) | 기대도수 (E_i) |
|---|---|---|
| 11–13세 | 9 | 7.4 |
| 13–14세 | 11 | 13.8 |
| 14–15세 | 10 | 9.5 |
| 15–18세 | 3 | 2.2 |
3단계: 카이제곱 통계량 계산
카이제곱 적합도 검정에서 사용하는 통계량은
\[X^2 = \sum_{i=1}^{k} \frac{(O_i - E_i)^2}{E_i}\]이며, 여기서는 구간 수가 $k = 4$ 이다.
각 항을 계산하면
- 11–13세: $\dfrac{(9 - 7.4)^2}{7.4} \approx 0.35$
- 13–14세: $\dfrac{(11 - 13.8)^2}{13.8} \approx 0.57$
- 14–15세: $\dfrac{(10 - 9.5)^2}{9.5} \approx 0.03$
- 15–18세: $\dfrac{(3 - 2.2)^2}{2.2} \approx 0.29$
따라서
\[X^2_{\mathrm{obs}} \approx 0.35 + 0.57 + 0.03 + 0.29 \approx 1.2\]즉, 관측된 카이제곱 통계량은 대략 $X^2_{\mathrm{obs}} \approx 1.2$ 이다.
4단계: 자유도(df) 계산
정규분포 $N(\mu, \sigma^2)$ 의 두 모수 $\mu$, $\sigma$ 를
데이터에서 추정했으므로, 자유도는
이 된다.
5단계: p-value와 결론
자유도 1인 카이제곱 분포에서
$X^2_{\mathrm{obs}} = 1.2$ 보다 오른쪽의 확률은
정도이다.
유의수준 $\alpha = 0.05$ 와 비교하면
- $p = 0.27 > 0.05$ 이므로
귀무가설(“정규분포가 데이터에 적합한다”)을 기각할 수 없다.
한 줄 요약
정규분포 $N(13.67,\; 0.89^2)$ 를 가정했을 때,
관측도수와 기대도수의 차이로 계산한 카이제곱 통계량은
$X^2 \approx 1.2$, 자유도 1, p-value 약 0.27이다.
p-value가 0.05보다 크므로 정규분포 적합성을 기각할 근거가 없고,
정규분포는 age at spermatogenesis 데이터에 대해
적절한 적합을 보인다.
Chi-square Goodness-of-Fit Test (Poisson)
월별 Guillain–Barré 증후군 사례 수 -
1. Problem (문제 정리)
The table below (Rosner, Chapter 4, with March 1985 excluded) shows the monthly number of Guillain–Barré syndrome cases in Finland from April 1984 to October 1985.
Use the chi-square goodness-of-fit test to assess whether a Poisson distribution is an adequate model for these data.
State your conclusion.
| Month (Year) | # Cases | Month (Year) | # Cases | Month (Year) | # Cases |
|---|---|---|---|---|---|
| April 1984 | 3 | October 1984 | 2 | April 1985 | 7 |
| May 1984 | 7 | November 1984 | 2 | May 1985 | 2 |
| June 1984 | 0 | December 1984 | 3 | June 1985 | 2 |
| July 1984 | 3 | January 1985 | 3 | July 1985 | 6 |
| August 1984 | 4 | February 1985 | 8 | August 1985 | 2 |
| September 1984 | 4 | — | — | September 1985 | 2 |
| Total months | 18 |
Goal (목표)
- 월별 사례 수가 평균
lambda를 갖는 포아송 분포(Poisson) 를 따른다고 볼 수 있는지 검정한다.
2. Step 1 – Hypotheses (가설 설정)
-
귀무가설 H0:
월별 Guillain–Barré 증후군 사례 수 X 는 어떤 평균lambda를 갖는 포아송 분포를 따른다.
즉,
X ~ Poisson(lambda) -
대립가설 HA:
이 자료는 포아송 분포를 따르지 않는다.
3. Step 2 – Estimate lambda (평균 추정)
먼저 총 사례 수와 월 수를 이용해 포아송 분포의 평균 lambda 를 추정한다.
모든 사례 수를 더하면:
3 + 7 + 0 + 3 + 4 + 4 + 2 + 2 + 3 + 3 + 8 + 7 + 2 + 2 + 6 + 2 + 2 + 6 = 66
- 월 수
n = 18 - 포아송 분포의 평균 추정값:
lambda_hat = (총 사례 수) / (월 수)
= 66 / 18
≈ 3.67
4. Step 3 – Observed Counts by Category (관측도수 정리)
각 월의 사례 수를 세면:
- 0 cases: 1 month
- 1 case: 0 months
- 2 cases: 6 months
- 3 cases: 4 months
- 4 cases: 2 months
- 5 cases: 0 months
- 6 cases: 2 months
- 7 cases: 2 months
- 8 cases: 1 month
카이제곱 적합도 검정에서는 각 칸의 기대도수(예상 개수)가 너무 작지 않도록 값을 묶어 사용한다.
여기서는 다음과 같이 4개의 구간으로 묶는다.
- 0–2 cases
- 3 cases
- 4 cases
- 5 이상 (5, 6, 7, 8…)
이때 관측도수(Observed, Oᵢ) 는:
- 0–2:
1 + 0 + 6 = 7 - 3:
4 - 4:
2 - 5 이상:
0 + 2 + 2 + 1 = 5
정리하면:
| Category (cases) | Observed count Oᵢ |
|---|---|
| 0–2 | 7 |
| 3 | 4 |
| 4 | 2 |
| ≥5 | 5 |
5. Step 4 – Expected Counts under Poisson (기대도수 계산)
lambda_hat = 3.67 인 포아송 분포를 가정하고, 각 구간에 속할 확률을 계산한 다음
이를 이용해 기대도수 Eᵢ 를 구한다.
5.1 Poisson probabilities (포아송 확률)
포아송 확률질량함수(PMF)는 다음과 같다.
P(X = k) = e^(-lambda) * lambda^k / k!
lambda = 3.67 을 대입해 필요한 값들을 계산하면 (계산 과정은 생략):
P(0) ≈ 0.0255
P(1) ≈ 0.0935
P(2) ≈ 0.1716
P(3) ≈ 0.2099
P(4) ≈ 0.1926
이제 구간별 확률을 계산한다.
-
0–2 cases:
P(0 ≤ X ≤ 2) = P(0) + P(1) + P(2) ≈ 0.0255 + 0.0935 + 0.1716 ≈ 0.2905 -
3 cases:
P(X = 3) ≈ 0.2099 -
4 cases:
P(X = 4) ≈ 0.1926 -
5 이상:
먼저 0–4까지의 누적확률을 구한다.
P(0 ≤ X ≤ 4) ≈ 0.0255 + 0.0935 + 0.1716 + 0.2099 + 0.1926 ≈ 0.6930그러면
P(X ≥ 5) = 1 − P(0 ≤ X ≤ 4) ≈ 1 − 0.6930 ≈ 0.3070
5.2 Expected counts (기대도수)
각 구간의 기대도수 Eᵢ 는
Eᵢ = n * P(해당 구간), n = 18
따라서:
E_0-2 = 18 * 0.2905 ≈ 5.23
E_3 = 18 * 0.2099 ≈ 3.78
E_4 = 18 * 0.1926 ≈ 3.47
E_≥5 = 18 * 0.3070 ≈ 5.53
정리하면:
| Category (cases) | Observed Oᵢ | Expected Eᵢ (Poisson, lambda = 3.67) |
|---|---|---|
| 0–2 | 7 | 5.23 |
| 3 | 4 | 3.78 |
| 4 | 2 | 3.47 |
| ≥5 | 5 | 5.53 |
모든 기대도수 Eᵢ 가 대략 5 이상이므로 카이제곱 근사 사용에 무리가 없다.
6. Step 5 – Chi-square Test Statistic (검정 통계량)
카이제곱 적합도 검정 통계량은 다음과 같다.
chi_square = Σ (Oᵢ − Eᵢ)² / Eᵢ
여기서 구간 수 k = 4.
각 항을 계산하면:
구간 0–2: (7 − 5.23)² / 5.23 ≈ 0.59
구간 3: (4 − 3.78)² / 3.78 ≈ 0.01
구간 4: (2 − 3.47)² / 3.47 ≈ 0.62
구간 ≥5: (5 − 5.53)² / 5.53 ≈ 0.05
따라서
chi_square ≈ 0.59 + 0.01 + 0.62 + 0.05
≈ 1.28
7. Step 6 – Degrees of Freedom & p-value (자유도와 p값)
자유도(df)는
df = (구간 수) − 1 − (추정한 모수 개수)
= 4 − 1 − 1
= 2
요약:
df = 2- 검정 통계량
chi_square ≈ 1.28
카이제곱 분포표 또는 계산기를 사용하면:
- p-value ≈ 0.53 (0.05보다 훨씬 큼)
- 95% 임계값은
chi_square(0.95, df=2) ≈ 5.99
따라서
1.28 < 5.99 → 귀무가설 기각 불가
8. Step 7 – Conclusion (결론)
유의수준 0.05에서,
- “월별 Guillain–Barré 증후군 사례 수가 포아송 분포를 따른다”는 가설을 기각할 수 없다.
즉,
이 자료에서는 포아송 모형이 틀렸다고 말해 줄 만한 통계적 증거가 없다.
따라서 포아송 분포는 월별 환자 수를 설명하는 데 충분히 적절한 모형으로 보인다.
기억해야할 것
카이제곱 검정은 관측된 데이터와 기대되는 데이터가 얼마나 다른지를 확인하는 도구이다.
연속형 데이터는 T-test, anova // 범주형 데이터는 카이제곱을 활용한다.
Reference : https://www.youtube.com/watch?v=lmNZr1EDyNA&t=60s