귀무가설
가정, 가설
T-Test
그 귀무가설을 검정하는 방법
표본 크기가 30이상이 되어도 사용하는데 문제없음
표본 크기가 크면 T-test와 Z-test가 거의 같아진다.
T-test는 표본의 수보다는 모집단의 분산을 알고 있는지가 중요
즉, 표본의 수가 작고 모집단의 분산을 모를 때 유용한 검정방식이 T-test.
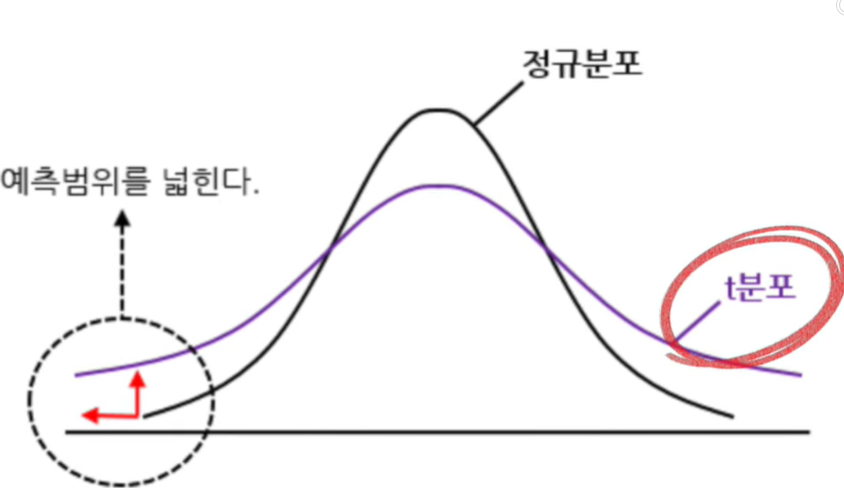
그 이유는 T-test가 사용하는 T-분포의 특징 때문이다.
정규분포는 평균 근처가 높고 꼬리가 얇은 반면에
T-분포는 평균 근처가 낮고 꼬리가 두꺼워 극단적인 값을 잘 반영한다.
즉, 작은 표본에서 발생할 수 있는 불확실성을 잘 반영하기 때문에 이런 상황에서는 T-test가 적절하다.
실제 사례
A반과 B반중 어떤 반이 수학을 잘하는지 검증해보자
A반은 12명을 뽑아 평균은 80점, 표준편차는 5점
B반은 10명을 뽑아 평균은 85점, 표준편차는 6점 이라고 가정했을 때,
평균 점수만 보면 B반이 더 잘해보이나 통계적으로 유의미한 결과일까?
만약, 표본 평균이 모집단의 평균과 같다면 이 통계는 유의미한 결과이지만 표본을 뽑을 때 A반에서 수학을 못하는 친구들만 뽑혔다면 ?
결과는 잘못된 결론일수가 있음!!
T-test는 결국 평균의 차이가 변동성에 비해 얼마나 큰지를 측정하여 이 차이가 우연일 가능성을 판단한다!
T-test의 종류
- 단일 표본 T-test
- 특정 값(전국 평균)과 표본 평균 비교
- 예를 들어, 한 학교의 수학 평균 점수와 전국 평균 점수가 유의미한 차이가 있는지 검증
- 독립 표본 T-test
- 두 독립적인 그룹의 평균 비교
- 예를 들어, A반과 B반의 시험 점수 평균이 유의미하게 다른지 확인
- 대응 표본 T-test
- 같은 그룹에서 두번 측정한 데이터 비교
- 예를 들어, 학생들이 학습법을 적용하기 전과 후에 치뤄진 시험점수의 차이를 비교
T-test 계산하기
B반의 평균이 A반의 평균보다 높은게 우연이 아님을 증명하기 위해 귀무가설 설정
귀무가설(H0) : A반과 B반의 평균 점수에 차이가 없다.
대립가설(H1) : A반과 B반의 평균 점수에 차이가 있다.
Z-Score를 활용하여 P-value가 유의수준보다 낮으면 귀무가설을 기각했듯이
T-test에서는 T-value가 T-분포표의 임계값보다 낮으면 귀무가설 기각
두 집단 평균 비교(등분산 가정) t-통계량은
\[t \;=\; \frac{\overline{X}_{1}-\overline{X}_{2}} {\sqrt{\,s_p^{2}\!\left(\frac{1}{n_{1}}+\frac{1}{n_{2}}\right)}} \qquad\]여기서 풀드(공분산) 표본분산은
\[s_p^{2} =\frac{(n_{1}-1)s_{1}^{2}+(n_{2}-1)s_{2}^{2}}{\,n_{1}+n_{2}-2\,}.\]두 그룹의 합동 표준편차를 계산하게 되면 \(\begin{aligned} s_p^{2} &=\frac{(12-1)(5^{2})+(10-1)(6^{2})}{12+10-2}\\ &=\frac{11\cdot25+9\cdot36}{20}\\ &=\frac{275+324}{20}=\frac{599}{20}=29.95 \end{aligned}\) 따라서
\(s_p=\sqrt{29.95}\approx 5.47.\) 이제 이 값을 이용하여 T값을 계산해보면
\[\begin{aligned} t &= \frac{80-85}{\sqrt{\,29.95\!\left(\frac{1}{12}+\frac{1}{10}\right)}} \\ &= \frac{-5}{\sqrt{\,29.95\times 0.183\overline{3}\,}} \\ &= \frac{-5}{2.34} \;\approx\; -2.13. \end{aligned}\]결론 도출
자유도와 유의수준:
\[\text{d.f.}=n_1+n_2-2=20\] \[\alpha=0.05\]따라서, T값 -2.13은 임계값 -2.086보다 작으므로 귀무가설을 기각하게 된다.