Part 1. 회귀분석 기본 개념
1. 회귀분석이란?
회귀분석(regression) 은
어떤 변수들이 다른 변수의 원인 역할을 하는지,
그리고 그 인과관계를 수학식으로 표현하는 방법이다.
- 원인이 되는 변수들: 독립변수 (explanatory variables)
- 영향을 받는 결과 변수: 종속변수 (response variable)
예시 표기:
x1, x2, x3, x4 → y
(독립변수들) (종속변수)
2. 회귀분석의 기본 분류
- 독립변수 개수에 따른 분류
- 독립변수 1개: 단순 회귀 (simple regression)
- 독립변수 2개 이상: 다중 회귀 (multiple regression)
- 독립·종속변수의 척도에 따른 분류
- 연속형·범주형 조합에 따라 다양한 회귀 모형 존재
(선형 회귀, 로지스틱 회귀, 포아송 회귀 등)
- 연속형·범주형 조합에 따라 다양한 회귀 모형 존재
- 관계 형태에 따른 분류
- 선형 회귀: 관계가 직선으로 표현되는 경우
예) y = a x + b - 비선형 회귀: 곡선으로 표현되는 경우
예) y = a x² + b, y = e^(a x) 등
- 선형 회귀: 관계가 직선으로 표현되는 경우
3. 선형 회귀의 직관적 의미
선형 회귀는
두 변수의 관계가 직선 형태라고 가정하고,
그 직선들 중에서 데이터를 가장 잘 설명하는 직선을 찾는 과정이다.
그래서 선형 회귀의 목표는 아주 단순하다.
데이터 점들을 가장 잘 대표하는 하나의 직선을 찾자.
4. 자동차 예시 (속도 → 제동거리)
예를 들어 보자.
- 자동차가 달리다가 브레이크를 밟는다.
- 브레이크를 밟은 순간의 속도: x (km/h)
- 완전히 멈출 때까지 이동한 거리: y (m)
우리의 직관:
속도 x 가 클수록, 제동거리 y 도 길어진다.
이 관계를 정량적으로 표현하고 싶을 때 회귀분석을 사용한다.
- 여러 번 실험해서 (xi, yi) 데이터를 모은다.
- 산점도를 그려 보면 오른쪽 위로 대체로 증가하는 패턴이 보인다.
- 이 점들을 “가장 잘 통과하는” 직선을 찾는 것이 선형 회귀다.
5. 잔차(residual)의 개념
직선을 하나 그렸을 때, 각 데이터 점은 대부분 직선 위에 딱 맞게 올라가지 않는다.
- 실제 데이터 점: (xi, yi)
- 직선이 예측한 값: ŷi = a xi + b
이때 잔차(residual) 는
잔차i = 실제값 − 예측값
즉,
잔차i = yi − ŷi
그래프 상에서는
- 점 (xi, yi) 와
- 직선 위 점 (xi, ŷi) 사이의 세로 거리가 된다.
잔차가 작을수록, 그 직선이 해당 점을 더 잘 설명한다고 볼 수 있다.
6. 최소제곱법(least squares)의 아이디어
질문:
“어떤 직선이 가장 데이터를 잘 설명할까?”
직관적으로는
모든 점들의 잔차가 전반적으로 가장 작은 직선이 좋다.
그래서 각 점에 대해 잔차를 구한 뒤, 잔차의 제곱을 모두 더한 값을 생각한다.
- 잔차i = yi − ŷi
- S = ∑ (잔차i)²
= ∑ (yi − ŷi)²
여기서 ∑ 기호는 “i = 1 부터 n 까지 전부 더한다”는 뜻이다.
최소제곱법의 목표
S(a, b) = ∑ (yi − (a xi + b))²
이 최소가 되도록 a, b 값을 선택한다.
잔차에 제곱을 하는 이유
- 부호(±)를 없애기 위해
- 미분으로 최소값을 찾기 편하기 위해
이렇게 해서 얻은 직선을 최소제곱 회귀직선이라고 부른다.
7. 최소제곱 회귀직선의 장점
-
인과관계를 수학적으로 표현
단순히 “연관이 있다” 수준이 아니라
y = a x + b
같은 식으로 정량적 관계를 표현할 수 있다. -
새로운 데이터 예측 가능
예를 들어 새로 측정한 속도가 x = 23 km/h 라면
회귀식에 넣어서 제동거리 y 를 예측할 수 있다.완벽히 정확하진 않아도 “합리적인 추정값”을 준다는 점에서 유용하다.
Part 2. ‘선형(linear)’이라는 말의 진짜 의미
1. 흔한 오해
처음 회귀를 배우면 보통
- x = 키, y = 몸무게
- 산점도 모양이 대충 직선
- 그래서 y ≈ a x + b 라고 두고 “선형 회귀”라고 부른다.
그래서 많은 사람이
“선형 회귀 = x와 y가 직선 관계일 때 쓰는 분석”
이라고만 이해하는데, 이는 반쪽짜리 이해다.
2. 선형 회귀에서 진짜로 선형이어야 하는 것
선형 회귀에서 중요한 것은
입력 x 가 아니라 “계수(파라미터)”에 대해 선형인지 이다.
모델이 다음처럼 생겼다고 하자.
ŷ = a · g1(x) + b · g2(x) + c · g3(x) + …
여기서
- g1, g2, g3 는 x 에 대한 어떤 함수여도 상관없다.
- 중요한 것은 계수 a, b, c 가 1차식으로만 나타난다는 점이다.
이렇게 “계수에 대해 1차식”이면 그 모델을 선형 모델(linear model) 이라고 부른다.
반대로, 계수끼리 곱하거나 제곱하면 비선형 모델이 된다.
예시
- y = a x + b → a, b 에 대해 1차식 → 선형 모델
- y = a x² + b x + c → x 에 대해서는 곡선이지만 a, b, c 에 대해 1차식 → 여전히 선형 회귀
- y = a² x, y = a b x → 계수끼리 곱/제곱 → 비선형 회귀
즉,
“선형 회귀 = 파라미터에 대해 선형인 회귀”
(입력 x 에 대해 꼭 직선일 필요는 없다.)
3. 특징 변환이 비선형이어도 선형 회귀일 수 있다
입력 x 를 그대로 쓰지 않고, 다음처럼 변형된 특징을 만들 수 있다.
- z₁ = x
- z₂ = x²
- z₃ = log(x + 1)
이때 모델을
ŷ = a₁ z₁ + a₂ z₂ + a₃ z₃ + a₀
라고 두면
- x 에 대한 그래프는 굉장히 복잡한 곡선이 될 수 있지만
- 식은 여전히 a₀, a₁, a₂, a₃ 에 대해 1차식이다.
따라서 이 모델은 여전히 선형 회귀다.
정리: “선형 회귀”는
원래 입력 x 에 대해 직선이라는 뜻이 아니라,
변환된 특징 벡터에 대해 계수들이 선형 결합된 모델이라는 뜻이다.
4. 왜 “파라미터에 선형”이 중요할까?
-
최소제곱 해를 깔끔하게 구할 수 있음
잔차 제곱합 S(w)가 볼록(convex) 형태가 되어서
미분이나 선형대수로 해를 안정적으로 찾을 수 있다. -
해석이 쉽다
계수 aₖ 하나하나가
“특징 하나가 y 에 미치는 영향”을 의미하기 때문에
계수의 부호와 크기로 해석이 가능하다. -
딥러닝의 기본 블록과 연결
신경망의 한 층도
y = W x + b 라는 선형 변환으로 볼 수 있다.
여기에 비선형 활성함수를 여러 층 쌓아 올린 것이 딥러닝이다.
5. “선형인지” 체크하는 기준
다음 질문에 “예”라고 답할 수 있으면 선형 회귀 모델이다.
“입력 x 는 어떻게 변형해도 좋다.
다만, 최종식이
a₁ h₁(x) + a₂ h₂(x) + a₃ h₃(x) + …
처럼 계수 a₁, a₂, a₃,… 에 대해 1차식인가?”
- Yes → 선형 모델 (선형 회귀)
- No → 비선형 모델 (비선형 회귀)
Part 3.선형회귀, MSE, 경사하강법, 등분산성
이제 머신러닝 관점에서 선형회귀를 정리한다.
1. 선형회귀 수식 (머신러닝 버전)
모델:
y = m x + b
- y : 예측하려는 값
- x : 입력값
- m : 기울기 (x 가 1 증가할 때 y 가 얼마나 변하는지)
- b : 절편 (x = 0 일 때 y 값)
2. 비용함수 – 평균제곱오차(MSE)
모델이 얼마나 잘 맞는지 숫자로 평가하기 위해 비용함수(cost function) 를 정의한다.
선형회귀에서 가장 흔하게 쓰는 것은 평균제곱오차(MSE) 이다.
- MSE = (1 / n) · ∑i=1n (yi − ŷi)²
여기서
- yi : i번째 실제 값
- ŷi : i번째 예측 값
MSE 가 작을수록 모델의 예측이 실제 값에 가깝다고 볼 수 있다.
MSE 를 그래프로 그리면 보통 위로 벌어진 U자 모양이 되고,
가장 낮은 지점이 “최적의 m, b” 에 해당한다.
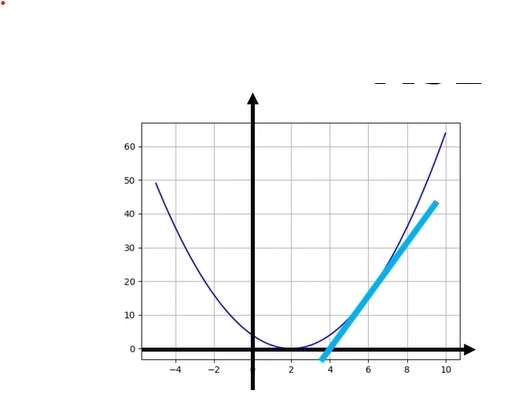
3. 경사하강법(gradient descent)의 직관
MSE 를 최소로 만드는 m, b 를 찾고 싶다.
해석적으로 공식으로 풀 수도 있지만, 머신러닝에서는 보통 경사하강법을 사용한다.
생각 방법:
- 산의 높이 = MSE 값
- 산의 위치 = (m, b)
- 산의 기울기(경사) = MSE 가 m, b 에 따라 얼마나 변하는지 (도함수)
경사하강법은
“현재 위치에서 기울기가 가장 급하게 내려가는 방향으로
한 걸음씩 내려가 보자”
라는 전략이다.
4. 경사하강법 업데이트 식
경사하강법의 핵심 아이디어:
- m 을 조금 바꿨을 때 MSE 가 얼마나 변하는지 → d(MSE)/dm
- b 를 조금 바꿨을 때 MSE 가 얼마나 변하는지 → d(MSE)/db
- 이 값들을 이용해서 m, b 를 “내려가는 방향”으로 업데이트한다.
형태만 쓰면
- m_new = m_old − α · d(MSE)/dm
- b_new = b_old − α · d(MSE)/db
여기서
- α (알파) : 학습률(learning rate)
- 한 번에 얼마나 크게 이동할지를 결정하는 스텝 크기
절차:
- m, b 초기값을 정한다.
- 현재 m, b 로 모든 데이터에 대해 예측 ŷi 를 계산한다.
- MSE 를 계산한다.
- d(MSE)/dm, d(MSE)/db 를 계산한다.
- 위 식대로 m, b 를 업데이트한다.
- MSE 가 충분히 작아질 때까지 2~5 과정을 반복한다.
| x | y | \hat{y} | error |
|---|---|---|---|
| 1 | 3 | 0.5 | 2.5 |
| 2 | 5 | 1 | 4 |
Cost function:
\[C(m,b) = \frac{1}{2}\Big( y_1 - (m x_1 + b) \Big)^2 + \frac{1}{2}\Big( y_2 - (m x_2 + b) \Big)^2\]Partial derivative with respect to (m):
\[\frac{\partial C}{\partial m} = \frac{\partial}{\partial m} \left[ \frac{1}{2}\Big( y_1 - (m x_1 + b) \Big)^2 + \frac{1}{2}\Big( y_2 - (m x_2 + b) \Big)^2 \right]\]Using the chain rule step-by-step:
\[\frac{\partial C}{\partial m} = \frac{1}{2} \cdot 2\Big( y_1 - (m x_1 + b) \Big)\frac{\partial}{\partial m}\Big( y_1 - (m x_1 + b) \Big) + \frac{1}{2} \cdot 2\Big( y_2 - (m x_2 + b) \Big)\frac{\partial}{\partial m}\Big( y_2 - (m x_2 + b) \Big)\]Since (\dfrac{\partial}{\partial m}(y_i - (m x_i + b)) = -x_i),
\[\frac{\partial C}{\partial m} = -\Big( y_1 - (m x_1 + b) \Big)x_1 -\Big( y_2 - (m x_2 + b) \Big)x_2\]Gradient w.r.t. m (example with two points)
\[\frac{\partial C}{\partial m} = \frac{1}{2} \Big( 2 \big( y_1 - (m x_1 + b) \big)(-x_1) + 2 \big( y_2 - (m x_2 + b) \big)(-x_2) \Big)\]Using (\hat{y}_i = m x_i + b):
\[\frac{\partial C}{\partial m} = \frac{1}{2} \Big( 2 (y_1 - \hat{y}_1)(-x_1) + 2 (y_2 - \hat{y}_2)(-x_2) \Big)\]Let (\text{error}_i = y_i - \hat{y}_i):
\[\frac{\partial C}{\partial m} = \frac{1}{2} \Big( 2 \,\text{error}_1\,(-x_1) + 2 \,\text{error}_2\,(-x_2) \Big)\]For the specific numbers
((x_1 = 1, x_2 = 2, \text{error}_1 = 2.5, \text{error}_2 = 4)):
Gradient w.r.t. b and update step
From the same cost function,
\[\frac{\partial C}{\partial b} = \frac{1}{2} \Big( 2 (y_1 - (m x_1 + b))(-1) + 2 (y_2 - (m x_2 + b))(-1) \Big)\]Using (\hat{y}_i = m x_i + b) and (\text{error}_i = y_i - \hat{y}_i):
\[\frac{\partial C}{\partial b} = -\text{error}_1 - \text{error}_2\]For (\text{error}_1 = 2.5, \text{error}_2 = 4):
\[\frac{\partial C}{\partial b} = -(2.5 + 4) = -6.5\]Gradient descent update:
\[b_{\text{new}} = b_{\text{old}} - \alpha \frac{\partial C}{\partial b}\]With (b_{\text{old}} = 0) and (\alpha = 0.01):
\[b_{\text{new}} = 0 - 0.01 \cdot (-6.5) = 0 + 0.065 = 0.065\]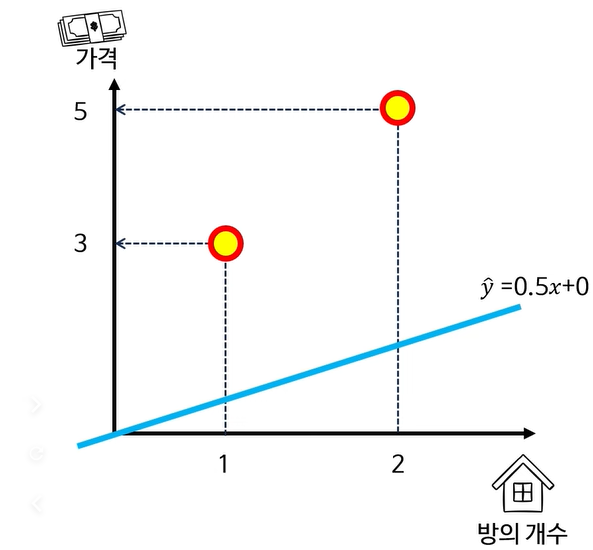
5. 간단 예시 흐름만 보기
데이터가 두 개 있다고 하자.
- (x₁, y₁), (x₂, y₂)
흐름:
- m, b 를 아무 값이나 정한다.
- 예측값 계산
- ŷ₁ = m x₁ + b
- ŷ₂ = m x₂ + b
- 오차 계산
- e₁ = y₁ − ŷ₁
- e₂ = y₂ − ŷ₂
- MSE 계산
- MSE = (e₁² + e₂²) / 2
- d(MSE)/dm, d(MSE)/db 계산
- 경사하강법으로 m, b 업데이트
- 다시 2~6을 반복 → MSE 가 점점 줄어든다.
6. 선형회귀의 중요한 가정 – 등분산성
선형회귀가 잘 작동하려면 몇 가지 통계적 가정이 필요하다.
그 중 하나가 등분산성(homoscedasticity) 이다.
입력값이 달라져도, 예측 오차(잔차)의 분산이
전체 구간에서 대체로 비슷한 수준이어야 한다.
조금 더 직관적으로 말하면:
- 회귀직선을 중심으로 데이터들이
x 전체 범위에서 비슷한 정도로 위아래로 흩어져 있어야 한다. - 어떤 구간에서는 오차가 매우 크고, 다른 구간에서는 매우 작다면
→ 구간에 따라 “흩어진 정도(분산)”가 크게 다르고
→ 그 구간에서 선형회귀의 예측력은 떨어지게 된다.
예:
- 방 4칸짜리 초호화 집은 “부르는 게 값”이라
방 개수와 상관 없이 가격이 랜덤하게 정해진다고 가정하면
이 구간의 데이터는 패턴이 없고 분산이 매우 크다. - 이런 구간에서는 “방 개수로 가격을 예측”하는 것이 큰 의미가 없다.
마지막 한 장 요약
- 회귀분석
- 독립변수가 종속변수에 어떤 영향을 주는지
수식으로 모델링하는 도구이다.
- 독립변수가 종속변수에 어떤 영향을 주는지
- 선형 회귀의 “선형”
- 입력 x 와의 관계가 직선이라는 뜻이 아니라
- 계수(파라미터)에 대해 1차식이라는 뜻이다.
- 머신러닝에서의 선형 회귀
- 모델: y = m x + b
- 비용함수: 평균제곱오차(MSE)
- 최적화: 경사하강법
- 통계적 가정: 등분산성 등
SST, SSR, SSE, MSR, MSE, F 통계량 정리
(단순 선형회귀 / ANOVA 분해 개념 정리)
1. 큰 그림: “총변동 = 설명된 변동 + 남은 변동”
우리는 보통 y 값들이 얼마나 흩어져 있는지(변동) 를 세 부분으로 쪼갠다.
- SST (Total Sum of Squares, 총제곱합)
- 데이터
y들이 전체 평균ȳ주위에서 얼마나 흩어져 있는지 - 즉,
y의 총 변동(total variability)
- 데이터
- SSR (Regression Sum of Squares, 회귀제곱합)
- 회귀선이 예측한 값
ŷ들이 평균ȳ주위에서 얼마나 흩어져 있는지 - 즉, 회귀모형(설명변수 X)이 설명하는 변동
- 회귀선이 예측한 값
- SSE (Error Sum of Squares, 잔차제곱합 / Residual SS)
- 실제값
y와 예측값ŷ의 차이(잔차e = y - ŷ) 제곱의 합 - 즉, 회귀선으로 설명하지 못한 변동
- 실제값
이 세 개는 항상 다음 관계를 만족한다.
SST = SSR + SSE
한 줄로 요약하면
전체 변동(= SST) = 모형이 설명한 변동(= SSR) + 모형이 설명 못한 변동(= SSE)
2. 표기 정리
- 관측값:
y1, y2, ..., yn - 평균:
ȳ(y_bar) - 예측값(회귀선):
ŷ1, ŷ2, ..., ŷn(y_hat) - 잔차(residual):
ei = yi - ŷi - 표본크기:
n
3. SST (Total Sum of Squares, 총제곱합)
정의
- 각 관측값이 평균에서 얼마나 떨어져 있는지, 그 제곱을 모두 더한 값
공식 (개념)
SST = Σ (yi - ȳ)^2(i = 1 ~ n)
해석
- “데이터
y가 전체 평균ȳ를 기준으로 얼마나 흩어져 있는가?” - 회귀모형을 쓰기 전에 존재하는 전체 변동량.
4. 회귀직선과 예측값 ŷ
단순 선형회귀에서 모형은
-
이론적(모집단) 모형
Y = α + βX + ε -
표본에서 추정한 회귀식
ŷ = a + bX
여기서
a: 절편(intercept)b: 기울기(slope)- 각 관측
xi에 대해ŷi = a + b * xi로 예측값을 만든다.
이렇게 구한 ŷ1, ..., ŷn 도 하나의 “데이터 집합”처럼 생각할 수 있다.
5. SSR (Regression Sum of Squares, 회귀제곱합)
정의
- 예측값
ŷ들이 평균ȳ주위에서 얼마나 흩어져 있는지
공식 (개념)
SSR = Σ (ŷi - ȳ)^2(i = 1 ~ n)
다른 표현 (단순 회귀에서 자주 쓰는 형태)
SSR = b * S_xy
(여기서b는 기울기 추정값,S_xy는 공분산에 해당하는 합)
해석
- 회귀선이 “평균만 사용하는 것”보다 얼마나 더 데이터를 잘 설명하는지에 대한 척도
- 즉, 설명변수 X 덕분에 설명되는 y의 변동량.
6. SSE (Error Sum of Squares, 잔차제곱합)
정의
- 실제값
y와 예측값ŷ의 차이(잔차)를 제곱해서 모두 더한 값
공식 (개념)
SSE = Σ (yi - ŷi)^2(i = 1 ~ n)
또는, 앞의 관계식에서
SSE = SST - SSR
해석
- 회귀선이 설명하지 못한, 남은 변동(unexplained variability).
- 잔차들이 클수록 SSE가 커지고, 회귀선이 데이터를 잘 못 설명하고 있다는 뜻.
7. MSR, MSE (Mean Squares)
분산분석(ANOVA)에서는 “제곱합(SS)”을 자유도(df) 로 나누어 평균 제곱(mean square) 를 만든다.
7.1 MSR (Mean Square Regression)
df_reg(회귀 자유도) = 설명변수 개수 = 단순 회귀에서는 1
정의
MSR = SSR / df_reg
단순 회귀의 경우
MSR = SSR / 1 = SSR
7.2 MSE (Mean Square Error)
df_res(잔차 자유도) =n - 2(단순 회귀에서: 절편 1개 + 기울기 1개 추정)
정의
MSE = SSE / df_res- 단순 회귀에서는
MSE = SSE / (n - 2)
해석
- 잔차들의 “평균 제곱”
- 즉, 회귀선 주변으로 y가 평균적으로 얼마나 흩어져 있는지를 나타내는 값
- 회귀모형에서 오차의 분산(σ²) 에 대한 추정량으로 사용됨.
8. F 통계량 (F-test for Regression)
이제 회귀모형이 통계적으로 유의한지 테스트하려면, F 통계량을 사용한다.
8.1 가설 설정
-
귀무가설 H0:
β = 0
→ X와 Y 사이에 선형 관계가 없다 (기울기가 0) -
대립가설 H1:
β ≠ 0
→ X와 Y 사이에 선형 관계가 있다
8.2 F 통계량 정의
F = MSR / MSE
자유도는
- 분자(df1) =
df_reg= 1 - 분모(df2) =
df_res=n - 2
8.3 해석
-
F 값이 크다 = 회귀가 설명하는 변동(MSR)이, 잔차 변동(MSE)에 비해 훨씬 크다
→ 회귀모형이 실제로 의미 있게 데이터를 설명한다는 증거가 강해짐. -
F 값이 작다 = MSR이 MSE와 비슷하거나 더 작다
→ 회귀선이 “그냥 평균 하나 쓰는 것”보다 딱히 나을 게 없을 수 있음
→ 기울기 β가 0이라는 귀무가설을 기각할 수 없음.
실제로는
- F 분포표 또는 소프트웨어에서 F( df1 = 1, df2 = n-2 )에 대한 p-value 를 구해서,
p < α (예: 0.05)면 → 귀무가설 기각 → 회귀선 통계적으로 유의함p ≥ α면 → 기각 실패 → 데이터 상으로는 유의한 선형 관계를 보이기 어렵다
9. 한 페이지 요약
- SST:
Σ (yi - ȳ)^2- y의 전체 변동
- SSR:
Σ (ŷi - ȳ)^2- 회귀모형이 설명하는 변동
- SSE:
Σ (yi - ŷi)^2또는SST - SSR- 회귀모형이 설명하지 못한 변동
- MSR:
SSR / df_reg(단순 회귀에서는df_reg = 1) -
MSE:
SSE / df_res(단순 회귀에서는df_res = n - 2) - F 통계량:
F = MSR / MSE- 자유도:
(df_reg, df_res) = (1, n-2) - F가 클수록, X와 Y 사이 선형관계가 유의하다는 증거가 강해짐.
- 자유도:
10. (참고) 11.1 예제 데이터에 적용하는 흐름
aplastic anemia 예제(망상적혈구 % vs 림프구 수)에서 실제로는 이런 순서로 진행:
ȳ계산 →SST = Σ (yi - ȳ)^2- 회귀계수
a, b를 구해서ŷi = a + b * xi계산 SSR = Σ (ŷi - ȳ)^2SSE = SST - SSRMSR = SSR / 1MSE = SSE / (n - 2)F = MSR / MSE구해서 F 분포와 비교 → 회귀 유의성 판단
title: Rosner 11.3–11.7 풀이 (Aplastic Anemia 회귀 예제) key: 2025-12-11-rosner-11-3-11-7 tags: [biostatistics, regression, rosner] lang: ko math: true —
Rosner 11.3–11.7 풀이 정리
Rosner 교재 11.1–11.7의 aplastic anemia 예제를 기반으로 한 단순 선형회귀 정리 노트입니다.
- (x): % Reticulocytes
- (y): Lymphocytes (per mm(^2))
- (n = 9)
데이터:
| 환자 | (x) (% Retic) | (y) (Lymphocytes / mm(^2)) |
|---|---|---|
| 1 | 3.6 | 1700 |
| 2 | 2.0 | 3078 |
| 3 | 0.3 | 1820 |
| 4 | 0.3 | 2706 |
| 5 | 0.2 | 2086 |
| 6 | 3.0 | 2299 |
| 7 | 0.0 | 676 |
| 8 | 1.0 | 2088 |
| 9 | 2.2 | 2013 |
0. 기본 요약 통계량
표본 평균:
[ \bar{x} = \frac{1}{9}\sum x_i = 1.40, \qquad \bar{y} = \frac{1}{9}\sum y_i \approx 2051.78 ]
제곱합들:
[ S_{xx} = \sum (x_i - \bar{x})^2 \approx 14.38 ]
[ S_{yy} = \sum (y_i - \bar{y})^2 \approx 3{,}616{,}477.56 ]
[ S_{xy} = \sum (x_i - \bar{x})(y_i - \bar{y}) \approx 1612.20 ]
단순 선형회귀 계수:
[ b = \frac{S_{xy}}{S_{xx}} \approx \frac{1612.20}{14.38} \approx 112.11 ]
[ a = \bar{y} - b\bar{x} \approx 2051.78 - 112.11 \cdot 1.40 \approx 1894.82 ]
회귀식:
[ \hat{y} = 1894.82 + 112.11 x ]
11.3 What is (R^2) for the regression line in Problem 11.1?
1) 정의
단순 회귀에서 결정계수 (R^2) 는
[ R^2 = 1 - \frac{\text{SSE}}{\text{SST}} = \frac{\text{SSR}}{\text{SST}} ]
- (\text{SST}) (Total SS) = 총 변동
- (\text{SSR}) (Regression SS) = 회귀로 설명되는 변동
- (\text{SSE}) (Error SS) = 남는(설명되지 않는) 변동
여기서는
[ \text{SST} = S_{yy} \approx 3{,}616{,}477.56 ]
단순 회귀에서
[ \text{SSR} = \sum (\hat{y}i - \bar{y})^2 = b \cdot S{xy} ]
이므로
[ \text{SSR} \approx 112.11 \times 1612.20 \approx 180{,}750.27 ]
따라서
[ R^2 = \frac{\text{SSR}}{\text{SST}} = \frac{180{,}750.27}{3{,}616{,}477.56} \approx 0.04998 \approx 0.05 ]
정답:
[ \boxed{R^2 \approx 0.05} ]
11.4 What does (R^2) mean in Problem 11.3?
방금 구한 (R^2 \approx 0.05) 의 의미:
림프구 수 (y) 의 총 변동 중 약 5%만
망상적혈구 비율 (x) (회귀 직선)로 설명된다.
- 남은 약 95%의 변동은
- 이 한 개의 설명변수로는 설명되지 않고
- 다른 생물학적 요인 + 우연한 변동 등에 의해 발생한다고 볼 수 있다.
- 따라서 이 예제에서 (x) 와 (y) 사이의 선형관계는 매우 약하다고 해석한다.
11.5 What is (s^2_{y \cdot x})?
표기 (s^2_{y \cdot x}) 는 회귀에서의 잔차 분산(오차분산 추정치) 이다.
[ s^2_{y \cdot x} = \frac{\text{SSE}}{n - 2} ]
여기서
[ \text{SSE} = \sum (y_i - \hat{y}_i)^2 = \text{SST} - \text{SSR} ]
이므로
[ \text{SSE} = 3{,}616{,}477.56 - 180{,}750.27 \approx 3{,}435{,}727.29 ]
자유도 (n - 2 = 9 - 2 = 7):
[ s^2_{y \cdot x} = \frac{3{,}435{,}727.29}{7} \approx 490{,}818.18 ]
표준편차 형태:
[ s_{y \cdot x} = \sqrt{s^2_{y \cdot x}} \approx \sqrt{490{,}818.18} \approx 700.6 ]
정답:
[ \boxed{s^2_{y \cdot x} \approx 4.91 \times 10^5} ]
(필요하면 (\;s_{y \cdot x} \approx 700.6))
11.6 Test for the statistical significance of the regression line using the t test.
이제 기울기 (\beta_1) 에 대해 t-검정을 한다.
1) 가설
-
귀무가설 (H_0: \beta_1 = 0)
→ 선형 관계 없음 (기울기 0) -
대립가설 (H_1: \beta_1 \neq 0)
→ 선형 관계 존재
2) 기울기 (b) 의 표준오차 (SE(b))
기울기 추정치 (b) 의 분산은
[ \mathrm{Var}(b) = \frac{s^2{y\cdot x}}{S{xx}} ]
따라서
[ SE(b) = \sqrt{\frac{s^2{y\cdot x}}{S{xx}}} = \sqrt{\frac{490{,}818.18}{14.38}} \approx 184.75 ]
3) t 통계량
[ t = \frac{b}{SE(b)} = \frac{112.11}{184.75} \approx 0.61 ]
자유도는
[ df = n - 2 = 7 ]
4) 결론
-
( t \approx 0.61) - 자유도 7의 t-분포에서 이 값은
p-value가 약 0.5 이상 (대략 (p \approx 0.56)). - 보통 (\alpha = 0.05) 기준에서
[ p > 0.05 \Rightarrow H_0 \text{ 기각 불가} ]
결론:
이 데이터에서는 기울기가 0과 다르다고 보기 어렵다.
즉, 망상적혈구 비율과 림프구 수 사이의 선형 관계는 통계적으로 유의하지 않다.
(참고: 단순 회귀에서는 (F = t^2).
앞에서 F-test로 구한 (F \approx 0.37),
지금 (t^2 \approx 0.61^2 \approx 0.37) 로 서로 일치한다.)
11.7 What are the standard errors of the slope and intercept for the regression line in Problem 11.1?
여기서는
- slope (b) 의 표준오차 (SE(b))
- intercept (a) 의 표준오차 (SE(a))
를 묻는다.
1) slope (b) 의 표준오차
이미 위에서 구한 값:
[ SE(b) = \sqrt{\frac{s^2{y\cdot x}}{S{xx}}} \approx \sqrt{\frac{490{,}818.18}{14.38}} \approx 184.75 ]
2) intercept (a) 의 표준오차
공식:
[ SE(a) = s_{y \cdot x} \sqrt{\frac{1}{n} + \frac{\bar{x}^2}{S_{xx}}} ]
여기서
- (s_{y \cdot x} \approx 700.58)
- (\bar{x} = 1.40)
- (S_{xx} \approx 14.38)
- (n = 9)
먼저 괄호 안:
[ \frac{1}{n} + \frac{\bar{x}^2}{S_{xx}} = \frac{1}{9} + \frac{(1.4)^2}{14.38} \approx 0.1111 + \frac{1.96}{14.38} \approx 0.1111 + 0.1364 \approx 0.2475 ]
따라서
[ SE(a) = 700.58 \times \sqrt{0.2475} \approx 700.58 \times 0.497 \approx 348.5 ]